R packages are like a little piece of software. One of the best practises of software development is to use unit tests and this is also possible for R packages using packages like testthat. I’m using testthat for the rim package and it’s been a great help. Everytime I change the code to add a new feature or fix a bug, I don’t have to worry too much about, whether the change I implemented happens to break something else. All I do is run my pre-defined test suite again and if nothing fails I can relax.
I learned from Hadley’s “R Packages”, that one should aim
… on testing the external interface to your functions - if you test the internal interface, then it’s harder to change the implementation in the future because as well as modifying the code, you’ll also need to update all the tests. – Hadley Wickhams
For rim v0.5.0 I spend a significant amount of time on figuring out what would be a good way to test graphical output. This version introduced the new feature of embedding the output of Maxima plotting commands when using the knitr engine, i.e. plot2d(), plot3d(), draw(), draw2d(), draw3d().
Since the first release, the knitr engine is tested using a test document test.Rmd. The idea is, to have an RMarkdown document that contains a number of Maxima code chunks. When running the test, this document gets rendered into a test.md using the implemented knitr engine for Maxima. So, all the code chunks are executed and the results are printed and formatted as Markdown.
Usually, one renders these documents into something more readable like a PDF or HTML file. In this case I decided not to do so, because
- we don’t want to actually read this document
- processing into PDF or HTML requires
pandocto be installed - the exact file would look different depending on a number of factors, such as the installed version of
pandocand the operating system.
After rendering, one can compute a hash value from the result (using package digest) and compare this hash value with the hash value of a reference document (result.md), which represent what we expect the document to look like. The implementation is like this:
test_that("maxima knitr engine works", {
fr <- system.file("extdata", c("test.Rmd", "result.md"),
package = "rim", mustWork = TRUE)
fo <- paste0(dirname(fr[1]), "/test.md")
hash <- digest::digest(readLines(con = fr[2]), "sha256")
suppressWarnings(knit(input = fr[1], output = fo, quiet = TRUE))
expect_match(digest::digest(readLines(fo), "sha256"), hash)
# clean up
file.remove(fo)
})This works nicely and across platforms!
However, when I started to embedd plots from Maxima, the above method stopped being applicable, because the md file only mentions the file path to the plot. Naturally so, because it’s just a simple text file.
Unfortuantely, rendering the md file into a PDF or HTML file, which then actually contains the image (e.g. as a base64 encoded string in case of HTML) is not a suitable solution. The reason is that the plots always look a tiny bit different depending on which platform you are running Maxima on. Also, because of differences in how fonts in plots are rendered and what version of gnuplot is installed. The entire hash changes as soon as a single bit changes in the file, even if you wouldn’t see this change in the resulting document. But, this is why they useful after all.
Here is an example plot generated from Maxima
(%i1) r: (exp(cos(t))-2*cos(4*t)-sin(t/12)^5)$
(%i2) plot2d([parametric, r*sin(t), r*cos(t), [t,-8*%pi,8*%pi]]);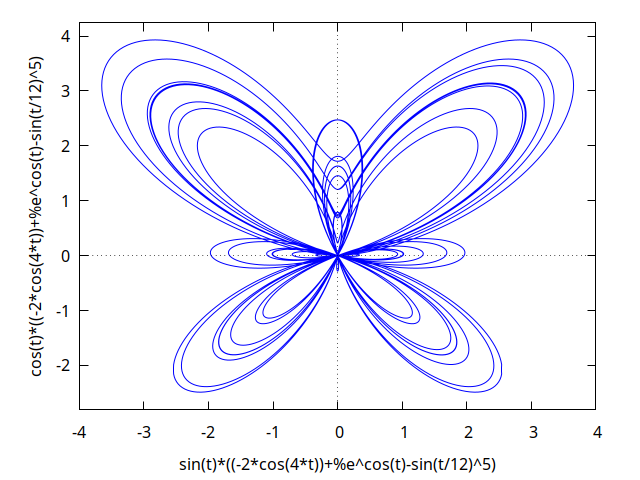
Figure 1: plot2d()
The test can be made however by (a) using percptual hashes, hashes specifially designed to work with images and (b) quantifying the number of bits of the hash that two images differ in order to allow for small differences. Luckily too, there is the R package OpenImageR:
library(OpenImageR)
# find the file name of the plot
img <- list.files(pattern = "(?:plot|draw)(2d|3d)?-[[:print:]]{6}\\.png", full.names = TRUE)
readImage() |>
rgb_2gray() |>
average_hash(, hash_size = 32, MODE = "binary")
the file name of a reference image
ref <- system.file("extdata", "plot3d-ref.png", package = "rim", mustWork = TRUE) |>
readImage() |>
rgb_2gray() |>
average_hash(, hash_size = 32, MODE = "binary")
if((d <- sum(abs(img - ref))) < 100) {
paste0("OK")
} else {
paste0("Not OK: ", d)
}In the example above, we are using average_hash() (there are other hashing functions as well like phash(), but I had no specific need for another). This hashing function computes a binary fingerprint of the given images, i.e. a matrix with dimension 32 rows and 32 columns (1024), each element being either 0 or 1. Doing this for both the resulting image and a reference image, we have 2 vectors of the same length, of which we can simply look at the sum of absolute differences and define a threshold value up until which we accept a deviation.
If the plot deviates more from what we expect to see plus a certain margin, then the string “Not OK: …” is printed instead of “OK”, which in turn alters the overall file hash of the test file and lets the test fail all together.
Just for fun, the average hash of the printed plot of size 8 is. The lower the size, the less sensitve the hash is for differences.
library(OpenImageR)
# find the file name of the plot
list.files(pattern = "(?:plot|draw)(2d|3d)?-[[:print:]]{6}\\.png", full.names = TRUE) |>
readImage() |>
rgb_2gray() |>
average_hash(hash_size = 8, MODE = "binary")## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14]
## [1,] 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [,15] [,16] [,17] [,18] [,19] [,20] [,21] [,22] [,23] [,24] [,25] [,26]
## [1,] 1 1 1 0 1 1 1 1 1 1 1 1
## [,27] [,28] [,29] [,30] [,31] [,32] [,33] [,34] [,35] [,36] [,37] [,38]
## [1,] 1 1 1 0 1 1 1 0 1 0 1 1
## [,39] [,40] [,41] [,42] [,43] [,44] [,45] [,46] [,47] [,48] [,49] [,50]
## [1,] 1 1 1 0 1 1 0 1 1 1 1 1
## [,51] [,52] [,53] [,54] [,55] [,56] [,57] [,58] [,59] [,60] [,61] [,62]
## [1,] 1 1 1 1 1 1 1 1 1 1 1 1
## [,63] [,64]
## [1,] 1 1PS.: Note the use of the naitive pipe operator (since R 4.1.0), much like the one imported by package magrittr.
Note: using a hash to detect differences as a unit test was criticized by CRAN, when a test failed (good!) on a certain platform. The criticism was that a hash-check doesn’t reveal what’s wrong and hence is less useful to others. I have since adopted a test that compares the raw text content of a resulting Markdown, whose error message prints lines that are different. Nevertheless, perceptual hashing is used to check whether plots are similar enough.